Чтобы хорошо ранжироваться в поисковых системах и занимать первые строчки выдачи, необходимо писать качественные тексты, которые будут лучше конкурентов. Одним из способов писать лучше, чем конкуренты, это делать тексты морфологически богаче. Что это значит?
Надо использовать как можно больше различных слов, фраз, технических и сленговых выражений, которые задают тематику.
Этим мало кто занимается, так как требует дополнительных временных затрат в работе над статьей, но приносит ощутимые результаты.
Например статья, сделанная с такой проверкой в высококонкурентной теме “Перевод по фото” дает трафика этому сайту около 400 чел/сутки. И это при нахождении статьи по основным запросам на 20-30 местах.
Почему так происходит? Из-за наличия объемной семантики текста, поисковики выводят в топ множество низкочастотных запросов.
В основном мы берем такие слова из ключевых фраз, которые нашли при составлении семантического ядра сайта. Как вы понимаете, отдельных слов получается очень много и нам надо как-то проверить их наличие в уже созданном тексте и причем всех сразу.
Это можно сделать легко и бесплатно.
Для этого воспользуемся возможностями сервиса Букварикс и текстового анализатора OverLead.
Что мы делаем в Буквариксе
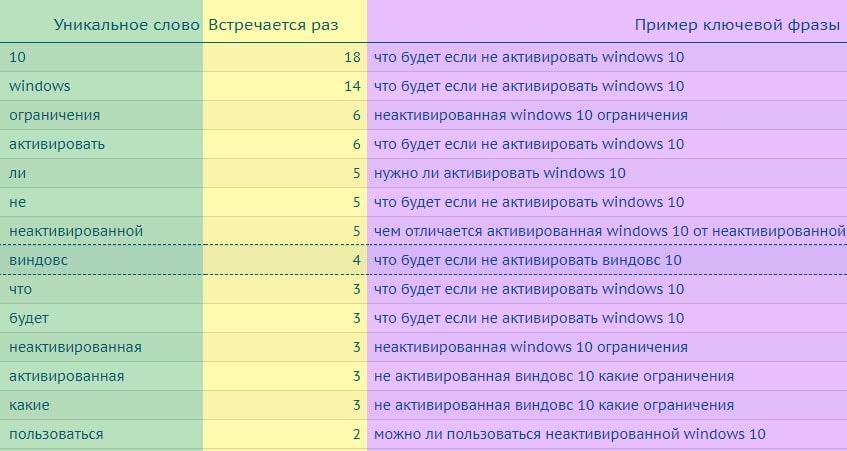
В Буквариксе мы разобьем ключевые фразы на отдельные слова ⇓
- На главной странице сайта Букварикс переходим в раздел “Инструменты” и выбираем пункт “Анализатор слов”(подсчет уникальных слов в списках).
- Вставляем в поле “Список слов” свои ключи и жмем кнопку “Получить”.
- После выполнения, вы получите список всех слов с частотностью их использования в ваших ключах. Его можно скопировать как в ручную, так и сохранить в формате CSV.
Что мы делаем в OverLead
В OverLead мы загрузим url проверяемой нами статьи и проверим на наличие в ней слов из полученного списка ⇓
- На сервисе Оверлид переходим в раздел “Инструменты” и выбираем пункт “Проверка вхождений”

- В специальное поле вставляем урл статьи и нажимаем “Получить”. Скорость вывода результатов зависит от объема статьи.
- После завершения сканирования, вам будет выдан результат, в котором отражено: Title, H1, H2-H6 и сам текст.
- Теперь нам осталось только вставить поисковые запросы в специально поле и нажать кнопку “Проверить”.

После окончания проверки, вы получите результат по наличию или отсутствию ключевых слов в вашем тексте и тегах.

Как видно из скана, слово корпус используется только в теле статьи (тег “b” зеленого цвета). В других тегах оно отсутствует (красный цвет). Но нам этого достаточно, так как это не основное слово. Есть упоминание и хорошо.
Так же мы видим, что отсутствуют полностью такие слова как “см” (сантиметры) и “мат” (сокращение от материнская плата). Это важные слова, которые относятся к тематике и их нужно хотя бы раз упомянуть в тексте или комментариях. Я их выписываю для дальнейшей доработки статьи. Слово “бывают” не относиться к теме, но для разнообразия его тоже можно куда-нибудь вставить или заменить им другое, более распространенное слово.
По количеству вписываемых уникальных слов и их словоформ, я ориентируюсь по их популярности в ключевых фразах (это дает Букварикс). Самые часто используемые стараюсь вписать во все теги и текст. Менее употребляемые лучше разнести в текст, комментарии, блоки вопросов и ответов или FAQ.
В качестве примера я проверил статью на вхождение слов про форм-факторы и размеры материнских плат. Всего ключевых фраз — 256. Уникальных слов в них — 170. Общая точная частота группы — 3196.

Надеюсь эта статья поможет вам улучшить свои тексты.

Классно. Вы меня просто спасли, когда подписка в МП Статс закончилась. Спасибо!!!
Очень рад, что помог.